Blogpost
An open distributed search engine for science
I’ve started building a distributed search engine for scholarly literature, which is completely contained within a browser extension: install it from the Chrome Web Store. It uses WebRTC and magic, and is currently, like, right now, used by 0 people. It’s you who can be number...
TL;DR: I’ve started building a distributed search engine for scholarly literature, which is completely contained within a browser extension: install it from the Chrome Web Store. It uses WebRTC and magic, and is currently, like, right now, used by 0 people. It’s you who can be number 0. This project is 20 days old and early alpha software; it may not work at all.
A few months ago, while attending Software Sustainability Institute’s workshop on software in reproducible research, I stumbled upon a problem. I was building a ruby-toolbox clone for scientific software, ScienceToolbox, which makes it easier for scientists to find the best software based on the number of software citations (link to repository or paper) and software quality (automated tests, stars and forks on GitHub, continuous integration, etc.). To my knowledge, such a service did not previously exist, which made it very hard to find great scientific software. In order for software to take its prime place among other research outputs, great scientific software should be cited and awarded, its authors cheered and famed, school wings and rainforest species named after them and more. But the basis for all of these aspects is that this amazing software can be found at all. This is what ScienceToolbox wants to solve.
But in order to do that, I need data about which software is used in what paper. And boy is this data hard to come by.
Imagine you’re trying to find new software in the field of ecology, specifically you’d like to know what cool things researchers are doing in combination with vegan, a great community ecology package. OK, so you basically want to get all papers citing vegan, get all links which point to software (e.g. CRAN, GitHub, Bitbucket) from these papers and then analyze trends which answer questions like:
- Which software has become increasingly popular in the past year?
- Which software’s popularity has waned?
- What was the most frequently used package in combination with
vegan?
So what do you do? What we all do. You Google it. Searching for vegan on Google Scholar gives 44,200 results, so if you could just query the Google Scholar API and... Oh! You can’t! It doesn’t exist! OK then, let’s scrape it, 44 thousand results shouldn’t be a problem for a regular scraper, and then we should be O...
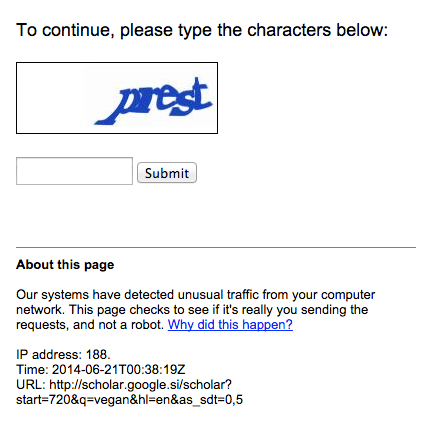
Aww shucks! Quickly you will be met with a screen similar to this. Scraping Google is a bad idea, which is quite funny as Google itself is the mother of all scrapers, but I digress. It looks like this approach is not going to work.
Fine, what else do we have? Well, there are a few open APIs (https://github.com/ScienceToolbox/code_citations/issues/6) out there, which have a fraction of the index that Google Scholar has, but you could query all of them and form a reasonable idea about what’s going on. But by using some of these APIs you could be subjecting yourself to some licenses you really do not want to sign (Peter Murray Rust on APIs). Wouldn’t it be cool if there existed an open & free API, which you could just query like so:
curl "http://mystery.project?q=http://CRAN.R-project.org/package=vegan"
And get a nice JSON back, containing your search results:
{
"status": "OK",
"results": [
{
"journal": "PLOS ONE",
"title": "Trustworthy-Looking Face Meets Brown Eyes",
"authors": "Karel Kleisner, Lenka Priplatova, Peter Frost, Jaroslav Flegr",
"abstract": "We tested whether eye color influences perception of trustworthiness. [abbreviated for blogpost]",
"year": "2013",
"doi": "10.1371/journal.pone.0053285",
"url": "http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0053285",
"id": "10.1371/journal.pone.0053285",
"method": "POST",
"links": [
"http://dx.doi.org/10.1037//0033-2909.126.3.390",
"http://CRAN.R-project.org/package=vegan",
[abbreviated]
]
},
{
"journal": "PLOS ONE",
"title": "Analysis of the Lung Microbiome in the “Healthy” Smoker and in COPD",
"authors": "John R. Erb-Downward, Deborah L. Thompson, Meilan K. Han, Christine M. Freeman, Lisa McCloskey, Lindsay A. Schmidt, Vincent B. Young, Galen B. Toews, Jeffrey L. Curtis, Baskaran Sundaram, Fernando J. Martinez, Gary B. Huffnagle",
"abstract": "Although culture-independent techniques have shown that the lungs are not sterile, little is known about the lung microbiome in chronic obstructive pulmonary disease (COPD). [abbreviated for blogpost]",
"year": "2011",
"doi": "10.1371/journal.pone.0016384",
"url": "http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0016384",
"id": "10.1371/journal.pone.0016384",
"method": "POST",
"links": [
"http://CRAN.R-project.org/package=vegan",
"http://www.r-project.org",
"http://dx.doi.org/10.1126/science.274.5288.740",
[abbreviated]
]
},
...
]
}
That would indeed be neat!
Well, the wait is over! This is what I've started building over the past two weeks - say hi to Scholar Ninja!

Whoah, what is this thing and how does it work?
Scholar Ninja is, in its essence, an entirely distributed search engine. There’s a few running distributed search engines out there, for example YaCy and FAROO, and they’re great! The only trouble is that in order to participate in the network, you need to install and run special software on your computer, which presents a (too) big barrier for most users, so the growth of these networks is fairly slow. Let there be no mistake, distributed search engines are really hard, and it’s likely that without many optimizations, they’re not even feasible (Li 2003), so the successes that YaCy and FAROO have had are phenomenal, especially considering this "uphill battle" perspective.
What makes Scholar Ninja unique, though, is that all of its functions (indexing, searching, and distributed server) are contained within a browser extension.
"What?", I can hear you say, "How can that be? Since when can a browser be a server?" Since 3 years ago, when the almighty WebRTC was born.
OK, WebRTC, distributed, magic, got it. Tell me more!
Scholar Ninja currently exists as a Chrome (33+) extension (http://github.com/ScholarNinja/extension), you can go ahead and install it from here, but beware that this is alpha software and may break completely. Also, you’re using this at your own risk. Exciting, isn’t it? Let me explain how it works, step by step.
1. Once you install the extension you’ll see a gray ninja in your extensions corner:
2. You’ll immediately join the Scholar Ninja Chord distributed hash table network using WebRTC as the transport layer (using webrtc-chord by the amazing Naoki). You can start searching by clicking on the ninja.
![]()
3. Try it out; if all goes well (and it’s really bound not to), you’ll get results from the network in a few seconds:

4. OK this is cool, but where do the results come from? From many nodes in the network! But how do they get into the network? Aha, good question! The secret is that every node is also an indexer. So when the ninja icon turns green it means the site you’re currently visiting is supported by Scholar Ninja and will be added to the index, so that everyone in the network will be able to search through it. And that’s it!
Scholar Ninja does not index sites you do not visit, so it doesn’t cause any additional load on publishers’ servers. Right now, PLOS, eLife, PeerJ and ScienceDirect are supported, so any paper you read from these publishers, while using the extension, will get indexed and added to the network automatically. It’s easy to add new publishers though: extractor.js. It’s also smart enough to not index papers where it detects that you do not have fulltext access. Fulltext is not added to the index though, only keywords are, so it is not possible to get the fulltext of a paper from Scholar Ninja, and this will never be possible. The purpose of this extension is to provide a free and open search engine and API for scholarly content, and not to circumvent legitimate paywalls.
Cool beans! Can I use it now?
You sure can, Sir/Madam Eager! Just install the extension here: https://chrome.google.com/webstore/detail/scholar-ninja/mngpckgljabecionknlpnnbamopcehgp?utm_source=blog. But there are miles to go before this hits version 1.0, so don’t be angry if it doesn’t replace your Google Scholaring just yet. As all of this is open source and under an MIT license, I am counting on you, the community member and master developer, to help out with bug-fixes and improvements, of which many will surely be necessary!
To name a few of the technical challenges, for those with the stomach for these things:
- When you are searching for multiple keywords, right now, the entirety of document ids containing this keyword will be transferred to you from the node that is responsible for this keyword, in order to find the documents which contain all of the keywords. This behavior is very hard to scale to thousands and millions of papers, and several optimizations will be needed: sending small Bloom filters instead of whole documents lists, implementing partial results, implementing optimized document list transferal (i.e. do not transfer everything to me, but perhaps make other nodes do partial intersections), and many others (Schwan 2009).
- In order to join the network, each joining node needs at least one other node in the network. This is done less than optimally right now (take the first peer and go from there) and is not foolproof.
- The weak point for scalability is a signaling server that is used to connect the nodes directly with WebRTC. It should be possible to establish WebRTC connections with other nodes without this signaling server, but using the DHT network as transport instead.
- To have an API, you need a standalone version of the extension, using node-webkit. This way you can open and listen to TCP sockets, so you easily create an HTTP server, which severs as the front-end for the WebRTC DHT network. I’ve done this already - Scholar Ninja standalone, but there are issues with WebRTC which need to be resolved (see #1526 of node-webkit), as right now a standalone node will be absolutely toxic to the network.
- If you have any ideas, please add them to http://github.com/ScholarNinja/extension/issues.
That’s all folks!

Update 22nd of June
Just fixed a bug which in certain network situations prevented the extension to rejoin the network (issue #2). A new build is available here: https://github.com/ScholarNinja/extension/raw/master/build/scholarninja-0.0.3.crx
Update 22nd of June #2
I published the extension on Chrome Web Store, to make it easier for people to stay up to date with the upcoming bug-fixes: https://chrome.google.com/webstore/detail/scholar-ninja/mngpckgljabecionknlpnnbamopcehgp?utm_source=blog
One thing I’m seeing right now is the formation of multiple networks within the system. A new network is created if there are no other existing peers, it seems to have happened that at a certain point no node was connected to the server, and the next node which connected thought that it has no friends, so it created network 2, while other peers continue to live on network 1. Need to figure out a better way of bootstrapping.
Update 3rd of July
The network is currently offline due to a "bug" in Chrome (or possibly the WebRTC spec), causing 100% CPU usage and consuming gigabytes of RAM, when the node has been running for a short while (hours). We've unpublished the extension until we can resolve this issue: https://github.com/ScholarNinja/extension/issues/7
Feedback
You can @ me on my personal Twitter or follow @ScholarNinja for updates. I also posted this to HN, so you can comment there as well.
Support
Enjoyed this post?
If you'd like to support my writing and experiments, you can do so on Ko-fi.