Blogpost
Can we speed up science with chat?
Combining real-time discussion between researchers with collaborative writing and data analysis, and the ability to publish very granular findings, could result in a major leap in the scale of collaboration and velocity of research...
TL;DR: Stubbornly refusing to acknowledge Betteridge's law, the answer to the above question is a resounding "yeah, probably". Combining real-time discussion between researchers with collaborative writing and data analysis, and the ability to publish very granular findings, could result in a major leap in the scale of collaboration and velocity of research.
For the past couple of years, I've been eagerly following the slow but relentless progress towards open science. With very few exceptions (e.g. this AI lab that's decided to stop publishing results in fear of a malicious use and hostile machine takeover), every step that the research community has taken has been towards increased openness of all things science-related. To name a few of those steps:
1. Many years ago, around the year 2002, open access became a thing, arguably starting this cascade of increased transparency. While we're still not entirely there (around 30% of papers are open access these days), open access is a global force that doesn't show any signs of stopping (1, 2, 3). The message from researchers is clear: papers we've written should be freely accessible by anyone anywhere.
2. Sometime later (although Wikipedia tells me I'm off by about 50 years), it was open data that came into the spotlight: Share the data you've collected and produced, and do it as openly and as freely as possible. The life of data doesn't end with the publication of your paper, containing merely one interpretation of it - it's possible that it's even more valuable in a different context. Even though open data only has a strong foothold in a small number of fields (e.g. machine learning, earth sciences, biology), we have a come a long way from closed data's heyday.
3. And sometime even later (with few extremely notable exceptions, e.g. arxiv.org starting in 1990), we started questioning ourselves about when the right time to publish something is. Preprint servers sprung up in various fields: biology, chemistry, sociology, to name a few, but there are many others. Authors are clearly enthusiastic about the ability to publish as soon as possible – and recent ideas, such as micropublications, providing a way to publish scoop-sized research, are taking that even further.
If we stand back a bit, observe the prevailing winds above the landscape, ignore the human building blocks of our research system (all of us), and ponder briefly on the nature of science itself, namely its iterative, step by small step progress towards objective knowledge, it's not difficult to see what an optimal global research "machine" would look like, if it could exist. All parts of this apparatus would freely and frequently use other bits of itself, sharing datasets, small and large, sharing approaches to analysing them and the computational resources to do so, sharing its hypotheses and ideas as quickly and often as possible.
As it stands, however, we humans are very much at the centre of the scientific endeavour and impossible to ignore. To see where the current sentiment lies, I've run a quick (and deeply unscientific) poll among researchers on Twitter: How close are we currently to the ideal of sharing early and sharing all?
Hey #openscience folks, how early in your scientific process would you feel comfortable sharing it? Reply if no answer fits. I’m testing a hypothesis here, help me out :)
— Jure Triglav (@juretriglav) December 15, 2018
To my surprise, more than half of people who responded would be willing to share their findings as soon as they have a hypothesis! And about a third of them are comfortable sharing even earlier, right at the start (the start of the scientific process or method, described at a very high level, consists of looking at various ideas and narrowing their scope until a hypothesis is found). Although the poll is quite biased by the readership of the #openscience hashtag, I thought those were pretty encouraging numbers!
To think about the result of the poll somewhat differently, it means that there are quite a number of researchers out there, who are ready and willing to become a part of the aforementioned optimal knowledge-generating machine, constantly sharing and collaborating on small pieces of science, journeying towards the objective truth as a team.
Well, why aren't they? I don't know about you, and I'd be very happy to be proven wrong with examples (I'll even add them here), but I haven't seen a single instance of someone sharing their hypothesis or research idea as soon as they occur. The earliest work I've seen anyone share is a draft or a preprint, a mostly fully fledged but unreviewed research paper. This could mean one of two things: one, either the poll above is wrong, and its question misunderstood, or two, there simply isn't an accepted (and also visible) channel for sharing these very early bits of knowledge effectively. I lean towards the latter.
As the closest proxy for early publication, let's consider preprints, more specifically, preprints in biological sciences. As seen in Figure 1 below, up until 2012, the number of deposited preprints was fairly steady, growing bit by very small bit every year, and it wasn't until 2013, when bioRxiv and PeerJ Preprints started, that those numbers rose meteorically.
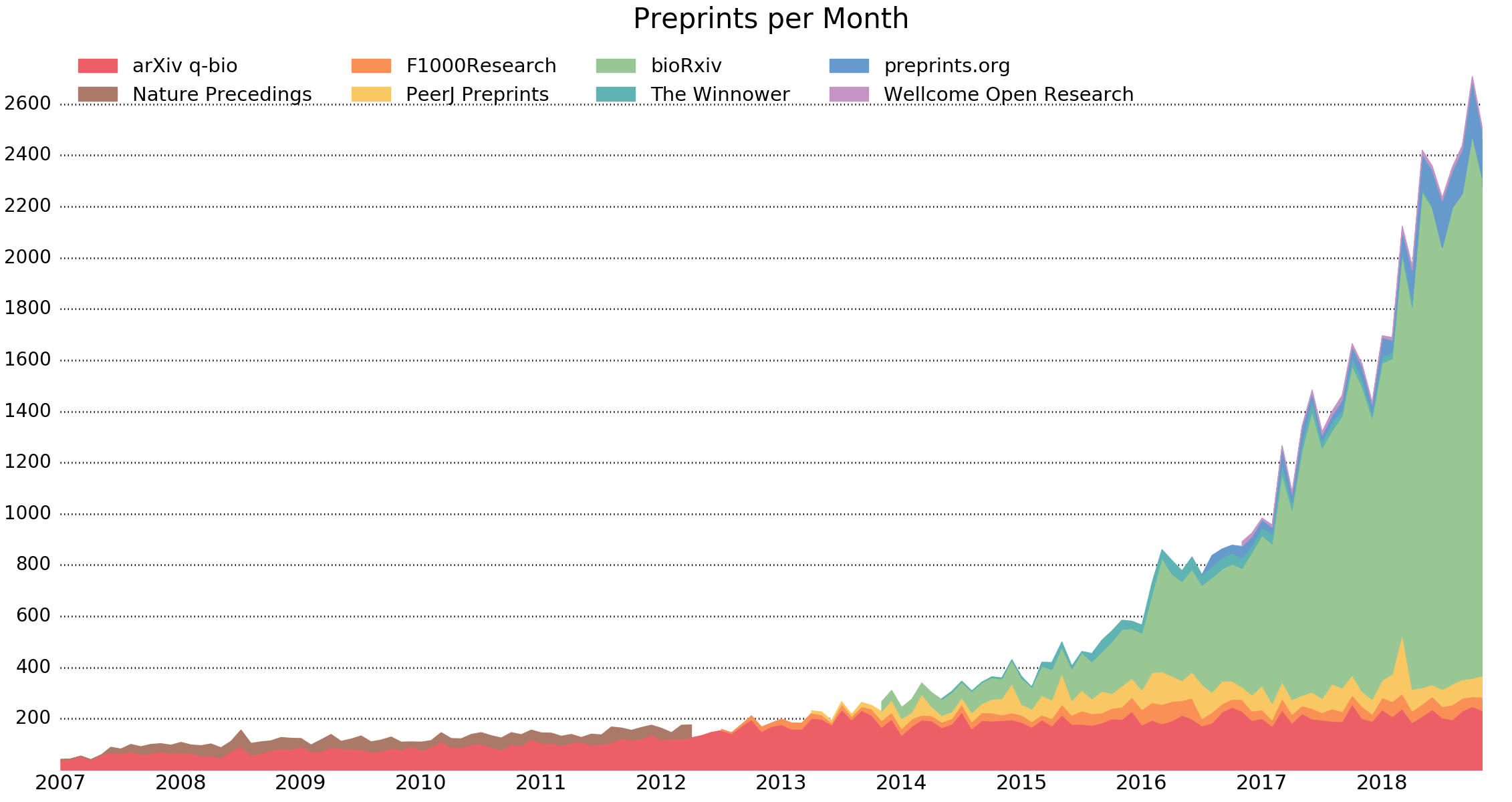
If you look at this chart real close, you can almost feel the pressure of the pent up demand to share knowledge, generated by the often slow and tedious "classical" publication process, releasing freely through preprint servers. Someone built a tap into the walls of academia and so a new conduit for open science was born, one that also shows absolutely no signs of stopping (4, 5). In other words, as soon as a channel to share preprint-stage bits of knowledge came into existence, that channel was used to do so. Additionally, nobody quite expected the hockey-stick quality of its growth.
Preprints are a great step in the right direction, but they are still quite far from the manifold small and early bits of knowledge that the machine we envisioned works best with.
So, allowing ourselves to dream just a little, we know that many researchers want to share findings with their colleagues and the world very early in the process of discovery. We also know that they generally don't. But we've also seen that just because they don't right now, doesn't mean that they won't, perhaps even soon and in large numbers. The rise of preprints shows that science is no longer immune to the explosive pace of cultural change seen frequently outside its walls.
How do we go from today to this magical tomorrow, where a researcher starts sharing at time 0, collaborates on their hypothesis with peers around the world, streams their collected data out to interested teams while experiment 1 is still underway, publishes many micropublications and cites many more – that and more, all in a day's work?
What's missing?
At the centre of all this is a crucial ingredient: communication. Going back, perhaps all the way to the early days of the republic of letters in the 15th century, and then stepping forward to the present time, looking at each technological leap along the way, from the printing press, the post, telegraph, telephone, to the internet, it's easy to see the massive impact each innovation had on the scale and reach of scientific communications. Well, except maybe when it comes to that last (but certainly not least) leap... While it's clear that the invention of the internet has changed just about all aspects of modern life, it often seems that science and scientific communication hasn't quite benefited as much as it could. Want to talk to your parents using real-time low-latency high-definition moving images from the other side of the planet? Sure! Rent an electric scooter off the curb with your phone and whizz around town silently? Yep, why not? Pay for coffee with your watch? Yes! Share early experimental data with peers in your research field? Uhm, well... wait, I know! I could tweet about it?
In many ways, science is communicated very similarly to how it was 100 or even 200 years ago. Yes, one can now read papers online instantly, but the process that leads up to the publication of a paper is assembled from parts that bear a strong resemblance to their historic pre-internet counterparts. If you'd have written down a workflow of a modern journal, and replaced the words "email" with "letter" and "PDF" with "printed manuscript", you'd have before you a process that Benjamin Franklin would be quite familiar with.
This is not to say that there is something necessarily wrong with that journal's workflow - in fact, it could be a sign of something being very right. A process virtually unchanged for hundreds of years? It's difficult to argue that it isn't working, and even more difficult to say, given science's accelerating pace, that it hasn't worked in the past. The lack of change is, however, still surprising. Especially as the internet was invented primarily for research.
As this tweet from 2015 eloquently puts it:
After a lab Slack chat about the anachronism of the scientific publication process, @cureffi explains it thusly: pic.twitter.com/cHr22ZXCcc
— Daniel MacArthur (@dgmacarthur) December 23, 2015
On the other side of the 'the transformative effect of the internet' scale, it's quite a bit more crowded. As an example, let's look at software development. It's a good example, as it is, looking at the highest level, an effort similar to science: an iterative, step-by-step, line of code by line of code, progress towards a solution. In science, you're walking towards objective truth. In software development towards a bug-free piece of software that solves a problem. It too existed before the internet, but its processes from that period are barely recognisable.

I mean, what even is that thing that everyone's pressing buttons on? OK, it's a keyboard, we still use those. But what are those things that everyone's staring at?! Alright, fine, it's a screen, we also still use those... So, the act of writing code might not have changed all that much (though there's new efforts in this space: 6, 7), but what happens almost immediately after? Today, instead of making a hole on the punchcard in the keypunch machine, those new bytes of text (sometimes even emoji 👍) make their way across the globe to central places where code is stored. As soon as they arrive, they can be read, reviewed and collaborated on with anyone on the planet. And they are! Open source software is an incredibly vibrant community, moving at an incredible speed. It's also a very international effort, to the point where it isn't even discussed or pointed out anymore - it's the default. Additionally, rarely do affiliations of contributors come into play - in open source you are you, and what matters is the contribution, not your employment status. But I digress!
Science, by comparison, is still not international by default, most of it is done within the cosy confines of your local lab, and when it is international, it's notable for it (8, 9). That's not to say that lab members aren't increasingly international, but that collaborating with a lab in a different country is still exceptional in most fields. Additionally, the feedback loops in science can sometimes be measured in years. By the time your work is shared, initially with a select group of your peers (the reviewers), you and your lab have already spent countless hours on it. And so, if the suggested changes received during that initial (but late) phase of sharing are extensive, they can be devastating. But in reality, it should be way more surprising to get only minimal corrections, given that what is being discussed is shared so late in the process.
Clearly, there are major differences between how software development and science are currently done, which is surprising given the high-level similarities between the two processes. However, if we go back 10 or so years, and try to compare the two again then, the differences become quite minimal. In 2009, both research and software development are done primarily within a local group (lab or company), both share results after completion (publication or software release) and both keep the "secret sauce" secret (data and code are mostly closed). Somehow, in the last 10 years, software development practices have changed dramatically, while science remains almost unchanged. This is not to say there haven't been improvements, merely that a major shift hasn't occurred yet.

So what gives? What caused software development to leap ahead in terms of its collaborative nature in only 10 years? In my mind, it comes down to a catalyst. A single well-positioned and well-executed catalyst. In 2008, GitHub was born (my own account dates back to 2010, when GitHub was already quite established), and suddenly, sharing code was perhaps even easier than not, it was easy to give and receive feedback, and it was easy to contribute to someone else's work and easy for someone else to contribute to yours. All of these things were possible before (though, for example, Git itself is only 15 years old), but with the introduction of GitHub, they were centralised and made easy. Someone built a tap into the walls of software development and so a new communication channel for open source was born, one that shows absolutely no signs of stopping. Sound familiar? (Also, my analogies are terrible.)
What's next?
In closing, given the above and the trends observed in the wider research community (the practice of sharing data becoming commonplace, the rise of preprints as a way to share earlier, reproducibility coming into focus in many ways, and labs increasingly using existing group chat solutions), the time is right to achieve a similar leap in scientific collaboration as occurred in software development with the introduction of GitHub.
I've gone on long enough in this post, so do stay tuned for part 2 - "The Mythical Catalyst - How Is It Made?" (mysterious uplifting music plays 🎶). Here are some keywords to set the mood: group chat, collaborative editing, integration with ORCID and the DOI ecosystem, integration with computing resources and tools for reproducible science...
This post was written in the spirit of sharing early, and I'd love to hear your thoughts and ideas about it (reach out at: me AT juretriglav.si or @juretriglav)!
Until next time! :)

References
- In win for open access, two major funders won't cover publishing in hybrid journals https://www.sciencemag.org/news/2018/11/win-open-access-two-major-funders-wont-cover-publishing-hybrid-journals
- Max Planck Society discontinues agreement with Elsevier https://openaccess.mpg.de/Elsevier-contract-discontinued
- Adoption of open access is rising – but so too are its costs https://blogs.lse.ac.uk/impactofsocialsciences/2018/01/22/adoption-of-open-access-is-rising-but-so-too-are-its-costs/
- The rise of preprints in biological sciences https://natureecoevocommunity.nature.com/users/169685-cheong-xin-chan/posts/39920-open-access-article
- The Preprint Dilemma http://science.sciencemag.org/content/sci/357/6358/1344.full.pdf
- The Humane Representation Of Thought http://worrydream.com/#!/TheHumaneRepresentationOfThoughtTalk
- Dynamicland https://dynamicland.org/
- CERN https://en.wikipedia.org/wiki/CERN
- European Bioinformatics Institute https://en.wikipedia.org/wiki/European_Bioinformatics_Institute
Support
Enjoyed this post?
If you'd like to support my writing and experiments, you can do so on Ko-fi.